KhmerType pushes more update on khmerocr.org that works more better with Khmer OS Battambang font with size of 26pt. It's good, I do hope the solution could work good enough for all legacy fonts: Limon, ABC etc. that in 90s there were so many documents written in that fonts.
The target documents, we should focus: Laws, Story books and many other education books in library.
Let's follow his post in his blog:
Khmer Type: Khmer OCR ត្រូវបានប៉ុន្មាន % ហើយ?: ថ្ងៃនេះ ខ្ញុំយកសៀវភៅ "ប្រវត្តិប្រជាជាតិខ្មែរ" ដែលវាយលើងវិញសម្រាប់ធ្វើសៀវភៅអេឡិចទ្រូនិច មកប្តូរទៅជាពុម្ពអក្សរ ...
Friday, November 7, 2014
Tuesday, October 14, 2014
First online TesseractOCR Engine Based for KhmerOCR
KhmerType just announced his online KhmerOCR implemented with TesseractOCR engine.
This year is the year of Tesseract OCR engine since every where, every researchers are focusing on it in Cambodia. The TesseractOCR is an opensource OCR engine maintained by Google. In few years ago, there are some people had tried to train Khmer characters with the engine since 2009 but the result was not good enough to go.
Today, Danh Hong, a team leader of his OCR project and well known as the Khmer OS fonts designer with Thim Rithy, moonOS (Unix Kernel OS) founder has announced his result with an online tool: khmerocr.org that allows people to try the scanned document to convert into Khmer Unicode text.
Currently he has asked for people to test and report error to improve the system.
I have taken some tests with my tested file that I have used in my previous research, the result needs a lot of time/tasks to improve.
All my below testing cases are using font: Khmer OS Content
Updated 15/10: Danh Hong helps to train the expected document and the result is good. (See in comment)


This year is the year of Tesseract OCR engine since every where, every researchers are focusing on it in Cambodia. The TesseractOCR is an opensource OCR engine maintained by Google. In few years ago, there are some people had tried to train Khmer characters with the engine since 2009 but the result was not good enough to go.
Today, Danh Hong, a team leader of his OCR project and well known as the Khmer OS fonts designer with Thim Rithy, moonOS (Unix Kernel OS) founder has announced his result with an online tool: khmerocr.org that allows people to try the scanned document to convert into Khmer Unicode text.
 |
| Web Base Interface: KhmerOCR.org |
Currently he has asked for people to test and report error to improve the system.
I have taken some tests with my tested file that I have used in my previous research, the result needs a lot of time/tasks to improve.
All my below testing cases are using font: Khmer OS Content
Case 1: Real Scanned Document (no much noise), font size: 32pt
The document is written in Khmer OS Content with font size 32pt, scanned on HP Scanjet G3110 with high resolution which is clear enough. The result is not yet good enough.
 |
| Case 1 : Scanned Document |
Case 2: Printed Text Using MS Paint (no noise), font size: 11pt
I tried this serious document since the size is around the use case of people using.
Even it has no noise but the result is not well enough yet.
 |
| Case 2: Printed Text with Small font size |
Case 3: Printed Text Using MS Paint (no noise), font size: 48pt
With this font size, in my method with printed text could product around 98% of accuracy. Here is also producing good result
These tests are only just one part of the font face and it is also a result for developers to improve.
I believe TesseractOCR would do more better when more training data are made but it would not produce 100% accuracy as people expected. We need more involvement to make this at least 95% of accuracy together for people to use. That's why OCR conference is formed.
Thank to Danh Hong and his team for this public initiation.
We are waiting other people's result as well.
Monday, October 13, 2014
Welcome to the Khmer OCR Conference, 28th October
The event is now announced to public, the Khmer OCR conference which is hosting at conference hall of Ministry of Posts and Telecommunication.
The OCR (Optical Character Recognition) software has been around in the world to convert the printed text on the image, pdf or scanned paper into the computed text or characters.
Khmer OCR topic has been in the researching phrase long time ago with some researchers already but most of the case, each researcher is trying to solve different issue in the OCR technologies such in as in segmentation (line or character separation), recognition or classification etc.
Now the conference is about to focus on producing the software that work for public uses, the invite all related researchers to discuss about different solution and TODO list for the next steps.
The event is for invited person only, please contact the host: research@niptict.edu.kh if you would like to participate.
The event only happens after some discussion and meeting with the team so far.

The OCR (Optical Character Recognition) software has been around in the world to convert the printed text on the image, pdf or scanned paper into the computed text or characters.
Khmer OCR topic has been in the researching phrase long time ago with some researchers already but most of the case, each researcher is trying to solve different issue in the OCR technologies such in as in segmentation (line or character separation), recognition or classification etc.
Now the conference is about to focus on producing the software that work for public uses, the invite all related researchers to discuss about different solution and TODO list for the next steps.
The event is for invited person only, please contact the host: research@niptict.edu.kh if you would like to participate.
The event only happens after some discussion and meeting with the team so far.
Tuesday, September 30, 2014
Want To Write Scientific Paper or Article, Start From Here
If you want to start writing that kind of research, you might need to learn about Structure, Format, Content, and Style of a Journal-Style Scientific Paper to get to understand around what you will write.
The following table is short snapshot to help you out, for the detail, please read this article.

The following table is short snapshot to help you out, for the detail, please read this article.
Sunday, September 28, 2014
Stay Tune, The OCR Conference is Delay Again
As receiving the update today, the venue informed us that the conference which was first delayed to 1st of October, it has been postponed again to end of October due to the invitation and want to have all potential researchers on board.
The invitation is promised to come by next week, wait and see.
The invitation is promised to come by next week, wait and see.
Monday, September 8, 2014
The 1st Khmer OCR Conference Changes to 1st October
Followup the information I have posted in my post recently, now the OCR team has delayed the conference to 1st of October instead due to short time on administrative matter at the venue.
During the conference there will be some presentations from the people in the article "The State of the Art of Khmer OCR" for their methods and then there will be about the future with "TesseractOCR" to plan.
Hope the team could make something different for our society and of course, everyone input will help.
I'll keep update if any change before the conference.






During the conference there will be some presentations from the people in the article "The State of the Art of Khmer OCR" for their methods and then there will be about the future with "TesseractOCR" to plan.
Hope the team could make something different for our society and of course, everyone input will help.
I'll keep update if any change before the conference.
Here is the picture of recent meeting (2nd Meetup)
1st Meetup
Thursday, August 21, 2014
OCR 2nd Meetup, Well done - Welcome to OCR Conference in September
Just back from the meeting of OCR Team, it was great.

The participants from various stakeholders:
Now it's time to be more open, I'll post more in detail but at first, book your available date for those who are interesting on presenting the Khmer OCR research or product; or even would like to join in the presentation of various researchers; The date on Tuesday 16th of September 2014, place will be inform soon.

There will be some invitations from the team to some individuals, group that the team aware about their work on OCR. There will be an announcement about this officially later soon.
The team is called: Khmer Natural Language Processing Consortium (Khmer NLP Consortium).
Are you interesting to join the conference? If you have any thing to make some different for our community, please come to join us.
The participants from various stakeholders:
- Universities: ITC, RUPP, NIPTICT
- NGO: OI
- Private Sectors/Individual: Myself
Now it's time to be more open, I'll post more in detail but at first, book your available date for those who are interesting on presenting the Khmer OCR research or product; or even would like to join in the presentation of various researchers; The date on Tuesday 16th of September 2014, place will be inform soon.
There will be some invitations from the team to some individuals, group that the team aware about their work on OCR. There will be an announcement about this officially later soon.
The team is called: Khmer Natural Language Processing Consortium (Khmer NLP Consortium).
It's all about opensource, open data, open idea and methods to make things different.
Are you interesting to join the conference? If you have any thing to make some different for our community, please come to join us.
Updated 08/09
- The conference changed to 1st of October, see this post
Saturday, August 2, 2014
We are in need of the product, OCR Project for Khmer Language
As I have been stated in previous article about "The State of The Art", KhmerOCR is always in researching state and no yet the ready product.
More recently, some groups are challenging this and welling to introduce the product by forming a concreted team for that. Together there are some individual team also are doing the same thing here.
The joint team by some universities and individual researchers was formed a meeting recently on 31st July.
Now it's not yet to detail how will be but it's great to see more people were happy and willing to contribute into the project for our Cambodia.
And yet a surprise, I just saw another project is presenting and on asking for funding: OCR Khmer, it seems to be an online tool, let's watch their promotional video:
According to the video, the online OCR project is likely to be running on printed image of the font size of 36pt.

The project is asking for funding of $4,000 at the website of gofundme.com.
It's great to see the product some where around, let's help him, you can click here for more info.
More recently, some groups are challenging this and welling to introduce the product by forming a concreted team for that. Together there are some individual team also are doing the same thing here.
The joint team by some universities and individual researchers was formed a meeting recently on 31st July.
Now it's not yet to detail how will be but it's great to see more people were happy and willing to contribute into the project for our Cambodia.
And yet a surprise, I just saw another project is presenting and on asking for funding: OCR Khmer, it seems to be an online tool, let's watch their promotional video:
According to the video, the online OCR project is likely to be running on printed image of the font size of 36pt.
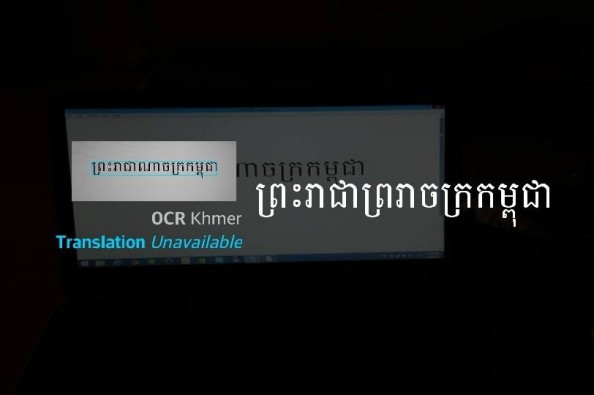
The project is asking for funding of $4,000 at the website of gofundme.com.
It's great to see the product some where around, let's help him, you can click here for more info.
Tuesday, July 29, 2014
Khmer Ligature Display Sample

A web page displaying the Khmer Ligature and it's about one page described about Khmer font.
Visit: http://www.wazu.jp/gallery/Fonts_Khmer.html
Tuesday, July 22, 2014
Excited to See Thing's On the Way [Blog]
I'm glad to see thing is on its way, glad to meet more people involve in the current issue.
I do hope the solidarity will bring thing out in a better result.
Let's dream! Let's plan!
I do hope the solidarity will bring thing out in a better result.
Let's dream! Let's plan!
Wednesday, July 2, 2014
Online Khmer Legacy Font to Unicode Converter
Online tool? Wow, you might interesting, we need this kind of such tools available for our Khmer people.
Here you can convert your legacy text (in Limon or ABC font) to Khmer Unicode, just right away.
Of course, currently, we're almost no more articles in legacy fonts since people are using Khmer Unicode already. But it might be sometimes, we need. Here is the tool for online converter in plain text from legacy font to Khmer Unicode.

Here you can convert your legacy text (in Limon or ABC font) to Khmer Unicode, just right away.
Of course, currently, we're almost no more articles in legacy fonts since people are using Khmer Unicode already. But it might be sometimes, we need. Here is the tool for online converter in plain text from legacy font to Khmer Unicode.
Tuesday, July 1, 2014
Kheng.info - Another Site of Khmer Tools
I saw this when a friend shares on facebook, it's so interesting to recommend more research blogs or site related to Khmer language matter.
Kheng.info is one website about that. There is a Khmer Segmentation tool which is about to work around 1000 characters. The website is built with around 3 millions line Khmer corpus and it's a dictionary website of English-Khmer and Khmer-English with audio in Khmer.

It would be an interesting website for other researchers or users to discover there.
Kheng.info is one website about that. There is a Khmer Segmentation tool which is about to work around 1000 characters. The website is built with around 3 millions line Khmer corpus and it's a dictionary website of English-Khmer and Khmer-English with audio in Khmer.
It would be an interesting website for other researchers or users to discover there.
Wednesday, April 23, 2014
State of The Art Of KhmerOCR Implementation
There aren't many articles when we search on the Internet about KhmerOCR topic, I, myself don't find a lot as well.
Of course, I believe that there are some people or companies might quietly in implementing the solution for that but without any announce I believe my presume below are relevant enough for people to understand about current situation of Khmer OCR.
Let's share around "State of The Art Of KhmerOCR" today ;)
I could find that, there are about several Khmer OCR researches being published through some organization, website and universities.
Solutions on OCR system, mostly focus on:
And there are some methods already used for Khmer OCR in
segmentation or recognition part such as
What we need for our Khmer language works for it, we need to analyze "how to train" our dataset.
I also did some training for Khmer as well for Tesseract for some letters, it seems that the system is good to go but there are some thing we need to aware before as I posted a question here.
I will try to write a post on how to train some characters that I did before.
Why Tesseract at this time?
Previous researches are mostly using their own combination of methods to solve various issue for Khmer language such as in segmentation or recognition but the pre-processing process (image processing) is also important for a real OCR system and its accuracy.
And I could see that Tesseract OCR is ready for all of that.
Is There Anyone Already Try for Tesseract?
Yes, you can search on Google, it has already been trying since 2009 per my search on Google and around.
And it might be already made by some universities or lecturers but remaining unclear for me.
So, Is There Any Ready Tesseract OCR for Khmer?
My presumed answer: No, I've never heard that there's a ready training set for Khmer yet to use in Tesseract OCR Engine.
But, just today, I checked again at the repo of Tesseract (14 January 2014), I saw some Khmer config is added (Files: Khmer.unicharset, Khmer.xheights), we need to test if they are working.
Therefore, Students, Lecturers, some NGO or community should take part to help this.
Of course, I believe that there are some people or companies might quietly in implementing the solution for that but without any announce I believe my presume below are relevant enough for people to understand about current situation of Khmer OCR.
Let's share around "State of The Art Of KhmerOCR" today ;)
I could find that, there are about several Khmer OCR researches being published through some organization, website and universities.
Methodologies
When we talk about Khmer OCR, we suppose around the solutions to make any characters from scanned images of handwritten, typewritten or printed text converts into machine-encoded text.Solutions on OCR system, mostly focus on:
- Pre-processing (usually is noise removal)
- Segmentation
- Line segmentation
- Character segmentation
- Recognition
- Mapping (Character Assembling)
- Lagendre Moment Descriptor,
- Wavelet Descriptor,
- Hidden Markov model (HMM),
- Back propagation,
- Scale Invariant Fourier Transform (SIFT),
- Fourier Descriptor, Hole detection
- Template Matching
- etc.
- And (it seems) the last one is: Support Vector Machine (SVM)
Literature Review/History
I might miss some others but here are what I could find about what have done so far with this topic.
If you, guys, have know some more, please share to people through comment form. I will check and update.
- The Khmer Printed Characters Recognition using Lagendre Moment Descriptor by Chey Chanoeurn et al got 92% of accuracy on 10 Khmer consonants including ប ព ជ ក ភ ណ ឃ ស វ and ឆ
- 2005, The Khmer Printed Character Recognition Using Wavelet Descriptors by Chey Chanoeurn et al got the accuracy of 92.85%, 91.66% and 89.27% on 10 types of Khmer fonts in 3 different sizes.
- 2008, The Khmer Segmentation for font Limon S1, size 22 by Ing Leng Ieng, PAN Localization Project got the accuracy of 99.11%.
- 2009, The Khmer OCR for Limon R1 Size 22 by Ing Leng Ieng from PAN Localization Project using framing and Discrete Cosine Transform calculation for recognition based on Hidden Markov Model and got the accuracy of 98.88%.
- 2011, The Khmer Optical Character Recognition (OCR) by Mr. Kruy Vanna using Fourier Descriptors, Component’s Holes, and Component’s Location got accuracy of 97.9% on 19 types of Khmer font.
- 2012, The Khmer Printed Character Recognition uses combining of Edge Detection and Template Matching by Iech Setha et al for one font “Khmer OS Content” with font size of 36pt got accuracy of 99%
- 2013, The Khmer Printed Character Recognition using Support Vector Machine (SVM) based, by Pongsametrey SOK for one font “Khmer OS Content” with font size of 36pt got accuracy of 98.54% (32pt = 98.62%, 28pt = 98.18%) with training set of font size: 32pt
Who are doing it nowadays
That's who I have known around in Cambodia only, it might be people who does some study abroad is also doing it. Anyway here what I have known:- Institute of Technology of Cambodia (ITC), It seems, there're some continuing implementation of KhmerOCR there
- Royal University of Phnom Penh (RUPP) also doing some more researches on this matter through students' researches, thesis and with their lecturers.
- Open Institute (Open Forum, KhmerOS.info), I believe that this topic is still interesting by this NGO
- And there are some other individuals as well as I heard (?)
What's Interesting
One opensource OCR engine, Tesseract OCR, it's a completed engine from the image processing to recognition and its output.What we need for our Khmer language works for it, we need to analyze "how to train" our dataset.
I also did some training for Khmer as well for Tesseract for some letters, it seems that the system is good to go but there are some thing we need to aware before as I posted a question here.
I will try to write a post on how to train some characters that I did before.
 |
| Few Training Char, All Are Error |
Why Tesseract at this time?
Previous researches are mostly using their own combination of methods to solve various issue for Khmer language such as in segmentation or recognition but the pre-processing process (image processing) is also important for a real OCR system and its accuracy.
And I could see that Tesseract OCR is ready for all of that.
Is There Anyone Already Try for Tesseract?
Yes, you can search on Google, it has already been trying since 2009 per my search on Google and around.
And it might be already made by some universities or lecturers but remaining unclear for me.
So, Is There Any Ready Tesseract OCR for Khmer?
My presumed answer: No, I've never heard that there's a ready training set for Khmer yet to use in Tesseract OCR Engine.
But, just today, I checked again at the repo of Tesseract (14 January 2014), I saw some Khmer config is added (Files: Khmer.unicharset, Khmer.xheights), we need to test if they are working.
Therefore, Students, Lecturers, some NGO or community should take part to help this.
Conclusions
The OCR system is very interesting for people nowadays.
We are using Khmer Unicode since it established in 2003 in the Kingdom and with Unicode, we have Google translate recently. Then, Khmer OCR should be also solved somehow as well.
We need more people to do it, to help, to share and publish.
---
Article Revision
- 23/04/2014: Initial the article
Remark:
- If any mistake in above research, please alert me in comment.
- More detail of each research, please find the published paper to read in detail
Monday, April 21, 2014
Finger Print Recorgnition, A Framework in C#
You might also interesting and there is an article to help us on that topic.
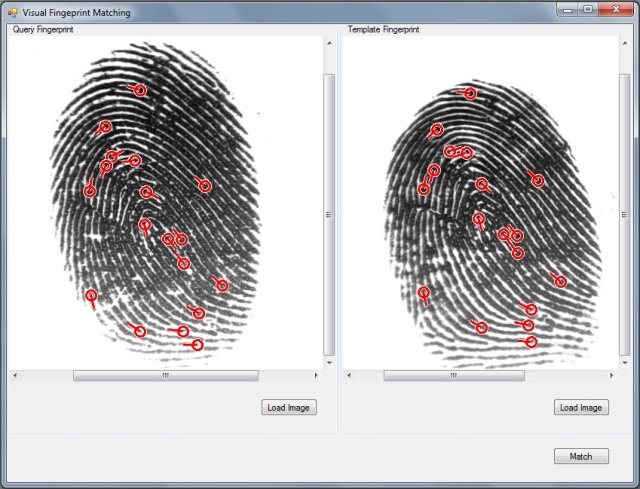
Fingerprint recognition is an active research area nowadays. An important component in fingerprint recognition systems is the fingerprint matching algorithm. According to the problem domain, fingerprint matching algorithms are classified in two categories: fingerprint verification algorithms and fingerprint identification algorithms.
This has been stated in CodeProject where you can find many articles related to .NET, it helps a lot.
If you want to go further, please read a newly published article: A Framework in C# for Fingerprint Verification
So if we want to have for Cambodia, example, to verify 1 person among 15 million people in Cambodia, above article can be a tool and machine learning can be a methodology to deal with huge data.
Tuesday, April 1, 2014
Inspired by a simple research - Save money by changing fonts
At Mashable, a research of 14-Year-Old student about "how much ink cost on publication", by choosing the right font.
This research should do the same for Khmer fonts.
Read at Mashable
Changing the standard typeface used by federal and state governments could save the United States roughly $370 million a year in ink costs, according to a peer-reviewed study by Suvir Mirchandani. The best part of the story? Mirchandani is just 14 years old.
Using software called APFill Ink Coverage, he calculated how much ink was used in four representative fonts — Century Gothic, Comic Sans, Garamond and the default choice of most word processors, Times New Roman.
The ink-preserving winner: Garamond.
This research should do the same for Khmer fonts.
Read at Mashable
Monday, March 31, 2014
KhmerOCR Development from ITC
There are few stakeholders are doing KhmerOCR, among them, researchers and students from ITC (Institute of Technology of Cambodia) are also doing it as well.
Here is one of a public presentation during Barcamp event about KhmerOCR introduced by ITC students/researchers.
There are other researchers from RUPP as well.
Here is one of a public presentation during Barcamp event about KhmerOCR introduced by ITC students/researchers.
There are other researchers from RUPP as well.
Thursday, February 13, 2014
Displaying Khmer - Development Document
By Javier Solar, 2004
The purpose of this document is to help developers who do not know the Khmer script to understand what is involved in displaying Khmer Unicode correctly.
Wednesday, February 5, 2014
Opensource: Khmer Logical Keyboard
Welcome to another Khmer opensource project on Khmer Logical Keyboard

The keyboard will provide three input states: Normal, Shift, and Long Press. And it will adhere to three principles:
About
The keyboard will provide three input states: Normal, Shift, and Long Press. And it will adhere to three principles:
- Khmer characters will be divided into 3 groups based on frequency of use:
- 1) set of frequently used characters will be assigned to the normal state.
- 2) less frequently used characters will be assigned to the Shift state of the layout.
- 3) characters rarely used in conversation, will be assigned to the Long Press state.
- It will not be a phonetic layout derived from QWERTY or AZERTY layouts.
- It will not include combined vowels and characters which are never used in conversation.
About
- Official Website: http://www.khmerkeyboard.com/
- Source Code: Google Code
Khmer Unicode Development - Letter to Mr. Maurice Bauhahn in 1996
According to Danh Hong's post, National Higher Education Task Force in 1996 had sent a letter to Mr. Maurice Bauhahn in order to register/integrate the Khmer language into computer system.
According to the Unicode.org website, Mr. Maurice Bauhahn has been called as one of the expert on Khmer Unicode:
Read the full letter here.
According to the Unicode.org website, Mr. Maurice Bauhahn has been called as one of the expert on Khmer Unicode:
Maurice Bauhahn is an expert on one of the most complex languages of Unicode 3.0 (Khmer), worked in Southeast Asia for 24 years, and holds a Masters of Science degree in Computer Science. [Unicode.org]So thanks to ministers who have involved on Khmer Unicode development.
Read the full letter here.
Monday, January 20, 2014
Khmer Protocols Research
I haven't read it into detail to give the information but here quickly share:
The presentation:
About
This is a set of protocols for doing genomic data analysis – specifically, de novo mRNAseq assembly and de novo metagenome assembly – in the cloud.
The latest released version of these protocols can always be found at:
By
The presentation:
About
This is a set of protocols for doing genomic data analysis – specifically, de novo mRNAseq assembly and de novo metagenome assembly – in the cloud.
The latest released version of these protocols can always be found at:
You are reading v0.8.4; please use the following URL in citations and discussions:
By
Brown, C. Titus; Scott, Camille; Crusoe, Michael; Sheneman, Leigh;
Rosenthal, Josh; Adina Howe (2013): khmer-protocols documentation.
figshare. http://dx.doi.org/10.6084/m9.figshare.878460
Saturday, January 18, 2014
Here is a blog for researchers
I met some people asking about where to find the articles about our Khmer research articles.
Just a short message here, it's one of my vision on that matter, when I started on my research on KhmerOCR topic, I really face this issue.
This blog will help to open on all researching articles related to the topic to help our Cambodia grows.
Let me know in comment if you are having some articles to share, passing the link or text if any.
Just a short message here, it's one of my vision on that matter, when I started on my research on KhmerOCR topic, I really face this issue.
This blog will help to open on all researching articles related to the topic to help our Cambodia grows.
Let me know in comment if you are having some articles to share, passing the link or text if any.
Monday, January 13, 2014
Paper - Mobile Tech for Improved Family Planning Services (MOTIF)
Background
Providing women with contraceptive methods following abortion is important to reduce repeat abortion rates, yet evidence for effective post-abortion family planning interventions are limited. This protocol outlines the evaluation of a mobile phone-based intervention using voice messages to support post-abortion family planning in Cambodia.
Access by URL: http://www.trialsjournal.com/content/14/1/427
© 2013 Smith et al.; licensee BioMed Central Ltd.
© 2013 Smith et al.; licensee BioMed Central Ltd.
Mobile Tech for Improved Family Planning Services (MOTIF), powered by our Verboice, an IVR tech http://t.co/wFohNwLIEd #cambodia #ictkh
— iLab Southeast Asia (@iLabSEA) January 14, 2014
Subscribe to:
Posts (Atom)